Tag: TACO
-
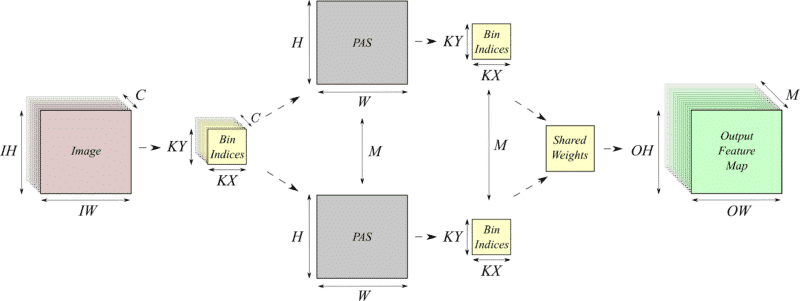
Second Ph.D. Paper Published by ACM TACO
Convolutional neural networks (CNNs) are one of the most successful machine learning techniques for image, voice and video processing. CNNs require large amounts of processing capacity and memory bandwidth. Hardware accelerators have been proposed for CNNs which typically contain large numbers of multiply-accumulate (MAC) units, the multipliers of which are large in an integrated circuit (IC) gate count and power consumption. “Weight sharing” accelerators have been proposed where the full range of weight values in a trained CNN are compressed and put into bins and the bin index used to access the weight-shared value. We reduce power and area of the CNN by implementing parallel accumulate shared MAC (PASM) in a weight shared CNN. PASM re-architects the MAC to instead count the frequency of each weight and place it in a bin. The accumulated value is computed in a subsequent multiply phase, significantly reducing gate count and power consumption of the CNN. In this paper, we implement PASM in a weight-shared CNN convolution hardware accelerator and analyze its effectiveness. Experiments show that for a clock speed 1GHz implemented on a 45nm ASIC process our approach results in fewer gates, smaller logic, and reduced power with only a slight increase in latency. We also show that the same weight-shared-with-PASM CNN accelerator can be implemented in resource-constrained FPGAs, where the FPGA has limited numbers of digital signal processor (DSP) units to accelerate the MAC operations.